Avaliando o resultado de uma IA
Avaliar aplicações de IA é crucial para garantir a qualidade e experiência do usuário. Verificamos a relevância e precisão das respostas geradas, a similaridade com respostas esperadas, além de outros indicadores de performance.


Se você trabalha com tecnologia e principalmente com desenvolvimento de software, deve ter percebido que os Large Language Models - LLMs oferecem um novo paradigma na forma de construir aplicações, os usuários passaram a ter como expectativa a utilização de linguagem natural como interface e não mais telas complexas para capturar suas ações. No entanto, por mais mágica que essa tecnologia possa parecer, devemos sempre avaliar as saídas geradas pelos modelos e com isso garantir o mínimo de qualidade desses retornos.
Avaliar as respostas de sistemas de IA, especialmente os baseados em LLMs, é importante porque os resultados produzidos por esses modelos são probabilísticos – ou seja, o mesmo prompt não produz necessariamente os mesmos resultados todas as vezes. Criar indicadores para medir a performance dos modelos é uma maneira de avaliar essas saídas, assegurando uma ótima experiência do usuário.
Neste post, apresento algumas maneiras para avaliar as saídas geradas por uma aplicação que utiliza um LLM usando o padrão Retrieval-Augmented Generation - RAG.
Processo de avaliação
Toda avaliação que se preze precisa de um processo para garantir que está comparando os parâmetros corretamente, afinal, não seria justo eu avaliar um peixe pela sua capacidade de subir em árvores ou um macaco pela sua habilidade em mergulho, certo?
Podemos começar criando um conjunto de dados de teste, uma base de perguntas que você espera que o modelo responda e as suas respectivas respostas, desta forma, teremos um ponto de partida para iniciarmos nossa avaliação. Podemos até usar um LLM para nos apoiar na elaboração dessa base - desde que tenhamos garantia de que as perguntas & respostas estejam corretas e sejam pertinentes ao teste em questão.
Uma vez que criamos nossa base de avaliação, devemos estabelecer os critérios pelos quais iremos avaliar o desempenho do modelo. Na realidade, nós não avaliamos o modelo em si, mas nossa habilidade de extrair uma boa resposta dele através do prompt que elaboramos. Como na maioria das vezes usamos uma arquitetura RAG para contextualizar o modelo e enriquecer nosso prompt, podemos usar alguns parâmetros desse padrão para medir essa performance.
A seguir proponho alguns indicadores que podemos utilizar para medir o desempenho desses sistemas, espero que entenda que essas métricas não são exaustivas e talvez possam não servir para todos os casos, mas entendo que pode ser útil para boa parte deles. Veja abaixo:
Encontrabilidade da informação (1)
Essa é principal função do repositório de conhecimento usado na RAG, devolver a informação necessária para contextualizar o modelo e ajudá-lo a responder às perguntas dos usuários. Portanto, avaliamos essa capacidade de encontrar todas as informações relevantes ao que foi questionado. Um grande número de respostas é um indicativo de que o sistema pode ter uma ampla gama de fontes e dados disponíveis, um item importante para a elaboração de respostas.
Precisão da busca (2)
Diferentemente da capacidade de encontrar a informação, devemos medir se o que o repositório nos trouxe é proporcionalmente suficiente para a elaboração do contexto que será enviado ao LLM, nosso foco aqui é a qualidade do filtro aplicado na busca, ou seja, o foco é avaliar se estamos trazendo a informação suficiente para contextualizar o modelo.
Relevância da busca (3)
Aqui fazemos um balanço das métricas anteriores, medimos se a quantidade de respostas retornadas e a qualidade das mesmas estão equilibradas para termos uma relação otimizada entre a extensão de respostas e a particularidade de cada item retornado.
Relevância das respostas (4)
Nesta fase, passamos a avaliar o resultado das respostas após o processamento do modelo. Com isso, avaliamos se a resposta retornada pelo LLM é relevante a questão colocada, simples assim.
Similaridade das respostas (5)
Neste ponto, avaliamos se a resposta gerada pelo LLM é compatível com a resposta esperada, aquela definida na nossa base de validação, isto é, levando em conta o significado do texto.
Precisão das respostas (6)
Outra métrica importante é a precisão das informações geradas pelo LLM, independente da similaridade, é importante termos uma métrica de precisão das respostas geradas pelo LLM. Isto garante a confiabilidade destes modelos como fonte de informação.
Como avaliar
O próximo passo é: como executar essa avaliação? A forma mais comum e natural é a manual, diretamente na interface da sua aplicação, porém é insano fazer isso, quando temos que avaliar mais de duas questões.
A abordagem é sempre usarmos um framework de testes e criarmos nosso roteiro de testes automatizados. Neste caso usaremos o próprio LLM como parte do processo.
Cenário de exemplo
Imagine que estamos criando uma aplicação que irá responder as dúvidas dos funcionários de um banco sobre os produtos que podem ser ofertados aos clientes, para isso realizamos a indexação do catálogo de produtos em um banco de dados vetorial, armazenaremos a descrição dos produtos, tarifas, pré-requisitos de contração e demais informações pertinentes.
Uma vez que organizamos essa base de conhecimento, vamos direcionar nossa aplicação RAG para usá-la como fonte.
Agora podemos estabelecer nosso script de testes da seguinte forma, no mínimo: Criamos um base de perguntas de teste, com as respectivas respostas esperadas. Para cada uma dessas perguntas, o script irá consultar a aplicação RAG e coletar as métricas que definimos anteriormente.
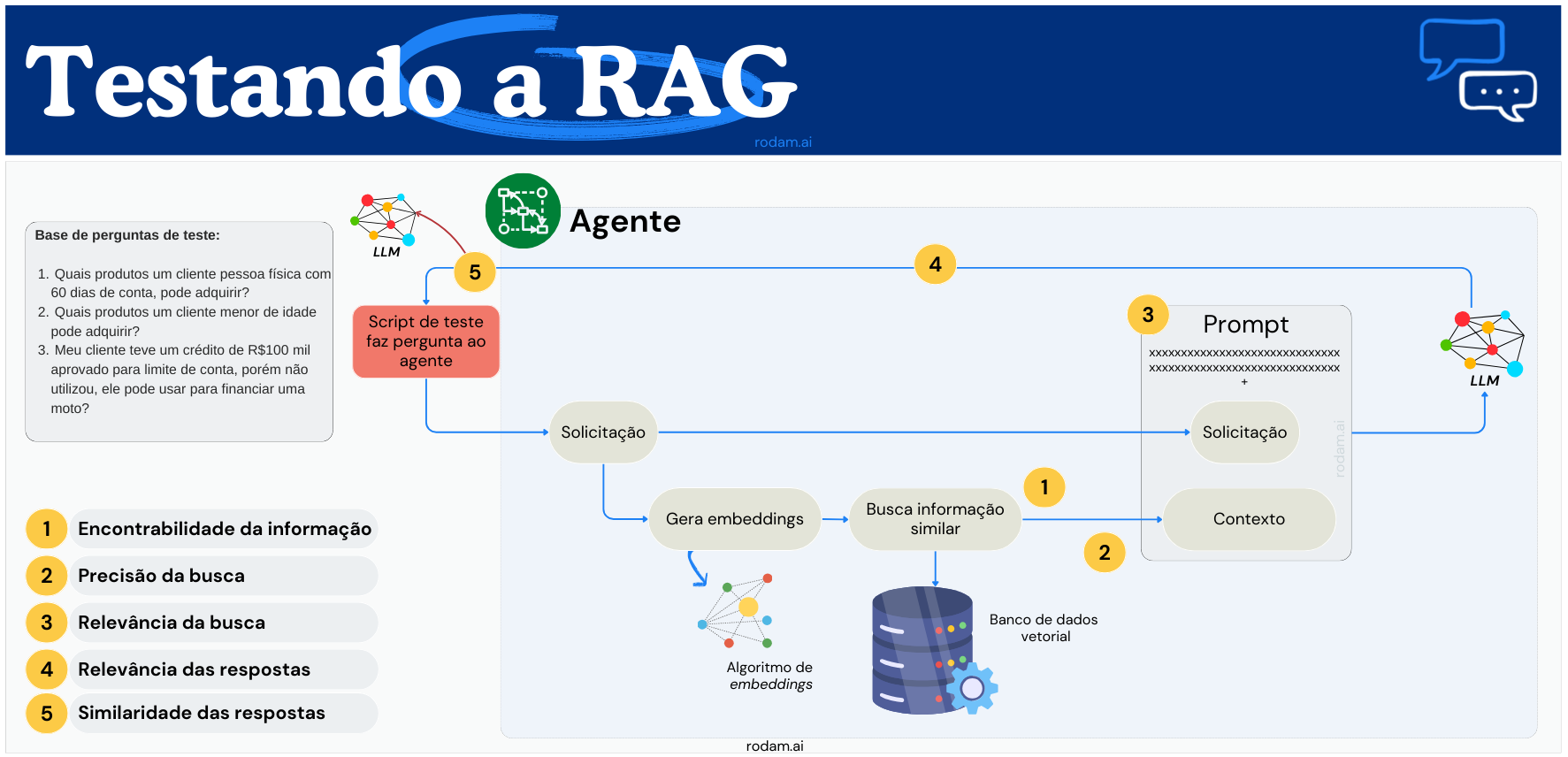
Imagine que para a primeira pergunta do nosso roteiro de testes: "Quais produtos um cliente pessoa física com 60 dias de conta, pode adquirir?", coletamos as seguintes métricas:
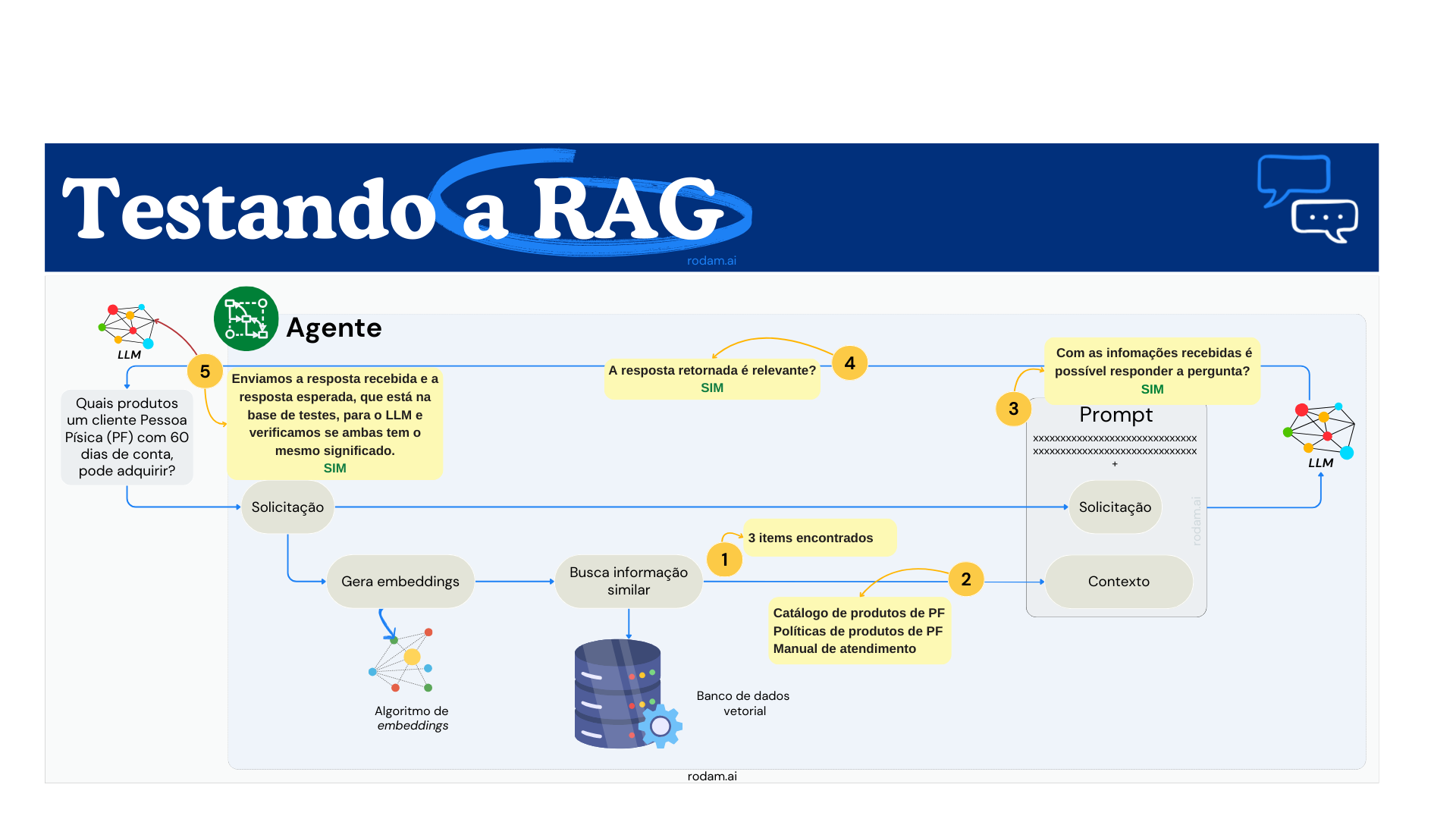
Perceba que para cada etapa do processo eu estipulei uma métrica. Os mais atentos já perceberam que esse "script" de teste, na verdade, irá disparar as perguntas contra o agente e conseguirá no máximo realizar a coleta da quinta métrica. Portanto, precisaremos interagir de forma mais profunda com o agente para acessar os demais indicadores, com isso devemos ter acesso ao resultado de cada etapa que desejamos coletar, isso pode ser feito através do log do próprio agente.
Apesar de ter apresentado seis métricas, o diagrama mostra apenas cinco, mas falaremos de todas elas nesse exemplo. Um ponto importante, não há uma ordem entre elas, eu apenas coloquei dessa maneira pois é a forma como o fluxo acontece.
Espero que você tenha notado que a primeira métrica é quantitativa, ou seja, achou informação? Quanto de informação achou? Já a segunda, é qualitativa: o que foi encontrado é pertinente ao que foi buscado? A terceirca métrica tem uma característíca qualitativa/quantitativa: a informação retornada, responde a questão? Sim, Não, Parcialmente? Como podemos automatizar essa checagem? Uma forma possível é armazenarmos em nossa base de testes a fonte de onde a resposta deve vir e conferir se é de lá que estamos pegando a informação para a construção do prompt.
Os indicadores que nosso script capturou até o momento avaliam o mecanismo de busca que irá entrega informação para o LLM. Após a elaboração do prompt e o processamento pelo LLM, podemos verificar se a resposta gerada é relevante, ou seja, responde a pergunta? Em outras palavras, a quarta métrica também é qualitativa.
Na quinta métrica proposta, nós comparamos se a resposta que recebemos do agente tem o mesmo significado da resposta que temos na base de testes para a pergunta que realizamos. Usaremos o LLM para fazer essa comparação! Podemos usar um prompt como o seguinte:
"Para a pergunta {pergunta}, as respostas a seguir, possuem o mesmo significado? Responda apenas com SIM ou Não. Resposta 1: {resposta_da_base_de_testes} - Resposta 2: {resposta_do_agente}"
Por fim, usamos uma métrica de precisão das respostas, ela não está no úlitmo diagrama, pois independentemente das demais nós sempre precisamos avaliar se a resposta é verdadeira. Essa avaliação é importante para garantir aos nossos usuários de que a IA é uma fonte segura de informação.
Requisitos não funcionais
Além das métricas propostas anteriormente, assim como a maioria dos sistemas, as aplicações de IA também possuem requisitos não funcionais que precisam ser medidos, pois são essenciais para o monitoramento da saúde do ambiente, neste caso, devemos levar em conta os seguintes indicadores: tempo de indexação de documentos, tamanho das bases, tempo de resposta da busca, tempo de criação do prompt, tempo de resposta do modelo, quantidade de tokens de prompt, quantidade de tokens de resposta, entre outros factíveis para o seu caso.
Visão completa
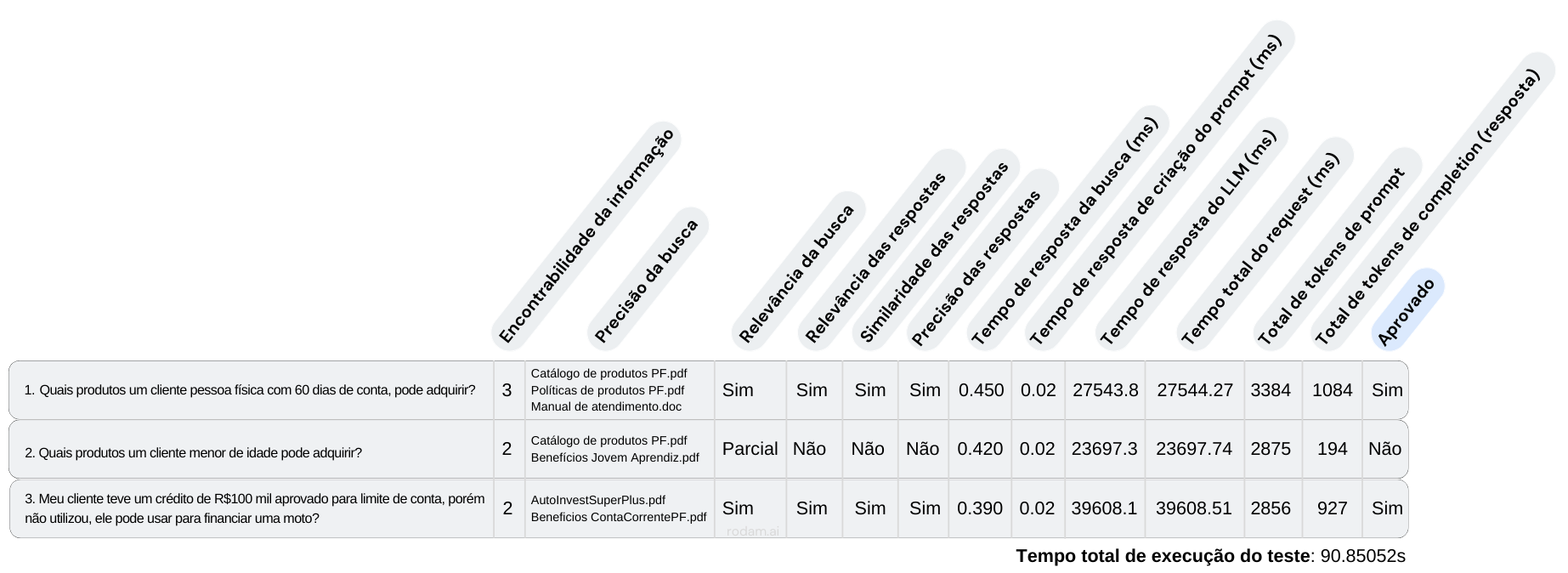
O resultado do um script de exemplo usando os indicadores propostos em uma visão mais completa ficaria algo similar ao quadro a seguir:
Conclusão
Espero que agora, avaliar a qualidade de uma aplicação de IA não seja mais um passeio no escuro. Além de possível, é crucial avaliar as respostas que recebemos dos sistemas que utilizam IA, principalmente aqueles que usam os LLMs. Notamos ainda, que ao utilizarmos uma abordagem RAG devemos encontrar a harmonia entre quantidade e qualidadede da informação retornada. Contudo, como todo processo, é um aprendizado contínuo. E é aqui que entra uma parte essencial do processo: você.
Compartilhe suas experiências e vamos descobrir o quanto ainda podemos extrair desses poderosos modelos. Quais desafios você encontrou? Como você melhorou a qualidade dos resultados? Faz parte do meu compromisso com a inovação aprender com as experiências valiosas daqueles que estão no campo, lidando com questões reais.
Se você encontrou valor neste artigo, não o guarde apenas para si mesmo. Compartilhe-o com seus colegas, seu time e com a comunidade de IA em geral. Ajudar-nos a espalhar o conhecimento que enriquece toda a comunidade. Cada compartilhamento, cada discussão, e cada feedback que recebo me ajuda a aprimorar. Compartilhe este artigo e junte-se à discussão!



