Como criar um copiloto usando IA - RAG
Aprenda como a IA pode atender às suas necessidades específicas, com a técnica de Retrieval-Augmented Generation - RAG. Mergulhe em uma jornada de inovação tecnológica, solucionando desafios da falta de informações contextuais e respostas genéricas


A Inteligência Artificial está transformando quase todos os setores, oferecendo acesso a soluções inteligentes para todos os tipos de negócios. Uma dessas inovações impressionantes é o Assistente Pessoal Inteligente. Mas já pensou em criar o seu próprio assistente de IA? Pode parecer algo retirado diretamente de um filme de ficção científica, mas o fato é que a construção de um assistente pessoal não é um sonho distante. Este artigo irá guiá-lo por um caminho simplificado para desenvolver o seu próprio assistente com IA, abrindo portas para um mundo onde a tecnologia atende às suas necessidades específicas. Então, prepare-se para mergulhar na jornada excitante de criar um assistente inteligente para você ou sua organização!
A ideia é explorarmos como funciona a criação de agentes de IA que interagem com informações privadas, ou seja, aquelas informações que apenas você ou sua organização tem acesso. Para isso usaremos uma abordagem chamada Retrieval-Augmented Generation - RAG, que consiste, basicamente, em darmos mais dados ao LLM no momento que pedimos uma tarefa.
Mas o que significa Retrieval-Augmented Generation?
Uma tradução direta do termo seria “geração aumentada de recuperação” o que, cá pra nós, não explica muita coisa.
Essa “Geração aumentada de recuperação” é uma técnica para melhorar as respostas de um LLM. Em vez de usar apenas o que foi aprendido durante o treinamento, o modelo busca ou “recupera” informações em uma base de dados confiável antes de responder. Os LLMs são modelos poderosos treinados com enormes quantidades de dados e são capazes de realizar várias tarefas, como responder perguntas, traduzir idiomas e completar frases, enfim, “gerar” conteúdo novo, porém não possuem todas as resposta, principalmente aquelas que estão fechadas no seu contexto específico.
A RAG aproveita essas capacidades e as amplia ou “aumenta”, permitindo que o modelo acesse informações específicas ou internas de uma organização sem precisar ser treinado novamente. Isso torna o uso desses modelos mais econômico e eficiente, garantindo que as respostas sejam mais precisas, atualizadas e úteis em diferentes situações.
Por que usar RAG?
Essa abordagem de solução proposta pela RAG, consegue eliminar diversos problemas que enfrentamos ao aprofundarmos no uso de LLMs no dia a dia, veremos os principais deles:
Falta de informações contextuais
Um dos primeiros fatores que podemos considerar para o uso da RAG, como já mencionei anteriormente, é a falta de informações contextuais que os modelos de linguagem sofrem. Eles conseguem responder facilmente questões genéricas sobre muitos assuntos, desde o como uma molécula se forma até como se deu o desenvolvimento do pensamento teológico no leste da Asia no século XIX. Porém, tem muita dificuldade de responder quais as cores de camisetas estão disponíveis para venda no seu catálogo, pois essa informação está restrita aos seus sistemas. Ao fornecermos dados contextualizados praticamente eliminamos essa deficiência.
Respostas genéricas
Uma vez que não possuem acesso a informações específicas sobre um determinado tema, os LLMs tendem a dar respostas genéricas e reduzimos essa situação entregando as informações específicas necessárias para a elaboração das respostas, diminuindo assim as chances de respostas genéricas serem entregues a um usuário.
Hallucinations
Outra característica dos modelos de linguagem é a geração de respostas falsas com um alto grau de confiança, no geral, isso se dá por informações divergentes ou ambíguas entregues ao modelo e a RAG pode auxiliar a enfrentar esse desafio. Porém, em alguns casos ela acaba potencializando essa característica, principalmente quando a base de conhecimento que está alimentando os modelos, está inconsistente.
Como a RAG funciona?
Apesar de parecer uma abordagem simples, é necessário alguns cuidados para que possamos extrair o máximo de benefícios, para tanto, devemos obedecer algumas etapas.
Novos dados
Dados externos ao treinamento do modelo são considerados novos e servem para alimentar o LLM com contexto para a tarefa solicitada. Nossa primeira tarefa é organizar esses dados, independentemente do seu formato - estruturados, como bancos de dados, ou não estruturados, como PDFs, multimídia, documentos do Office, etc. Devemos armazená-los em um repositório otimizado para consultas. Antes disso, utilizamos um algoritmo específico para converter esses dados em vetores, usando os conhecidos algoritmos de embeddings. Após este processamento, os dados são armazenados em um banco de dados vetorial, ideal para buscas rápidas, proporcionando respostas eficientes e contextualizadas geradas pela IA.
Já falei deles aqui: Como ajudar a IA a encontrar informações
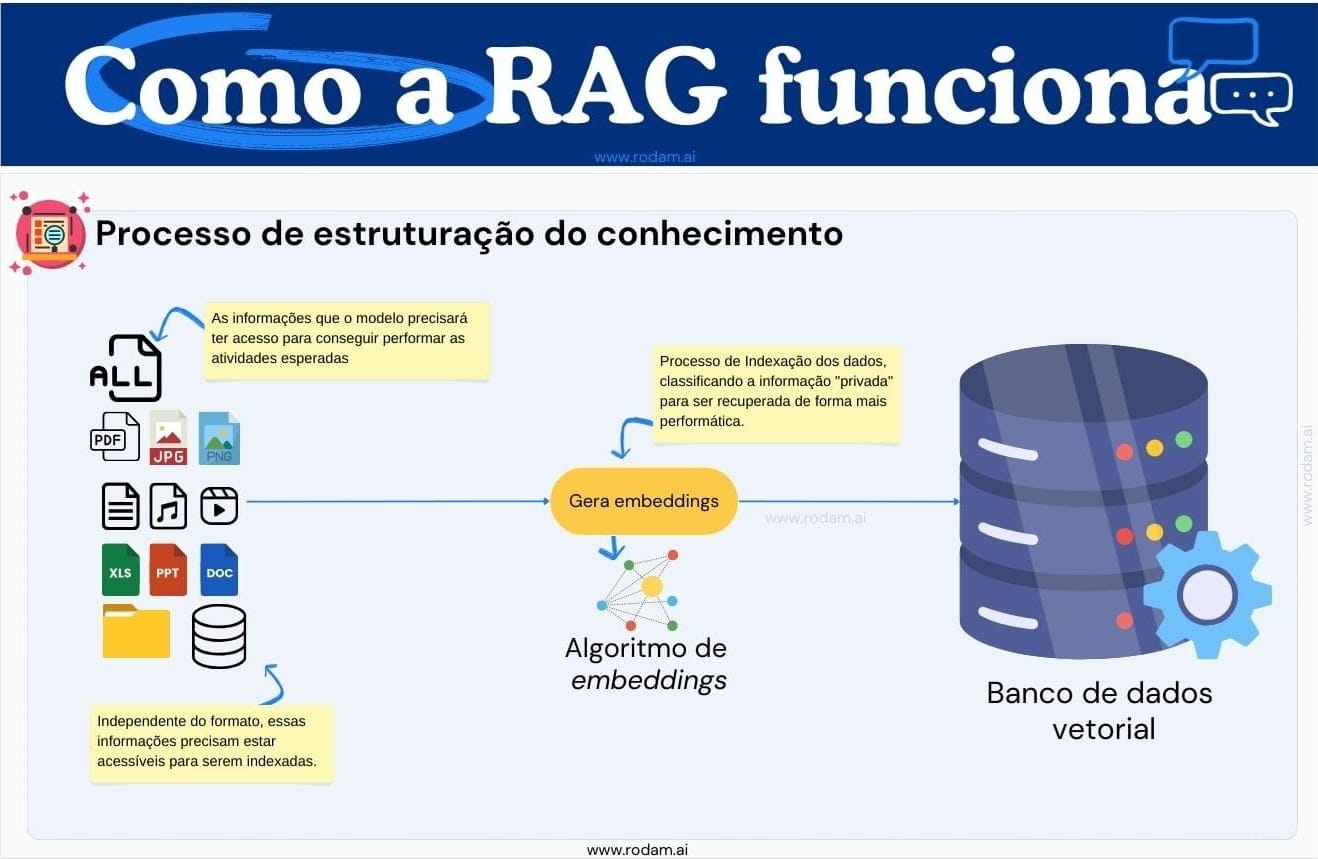
Busca de contexto
Uma vez que temos o conhecimento específico estruturado e armazenado em um repositório de alta performance, devemos trazer essa informação para a IA. Nesse momento o pedido do usuário é convertido em vetores e pesquisado no banco de dados vetorial. Vamos imaginar um bot que responda dúvidas sobre normas da empresa, se um colaborador perguntar: "Como faço para solicitar reembolso de alimentação em viagem pela empresa?", o sistema encontrará o documento da política da empresa que trata de reembolso de despesas de viagem e o manual do sistema de reembolso.
A relevância da pergunta feita com os documentos encontrados foi determinada pelo banco de dados vetorial.
Construindo o prompt
A seguir, usamos os conteúdos retornados pelo banco de dados vetorial para enriquecer o prompt que será enviado ao LLM e desta forma dar o contexto que falta para que ele responda com exatidão a tarefa passada, sacou?
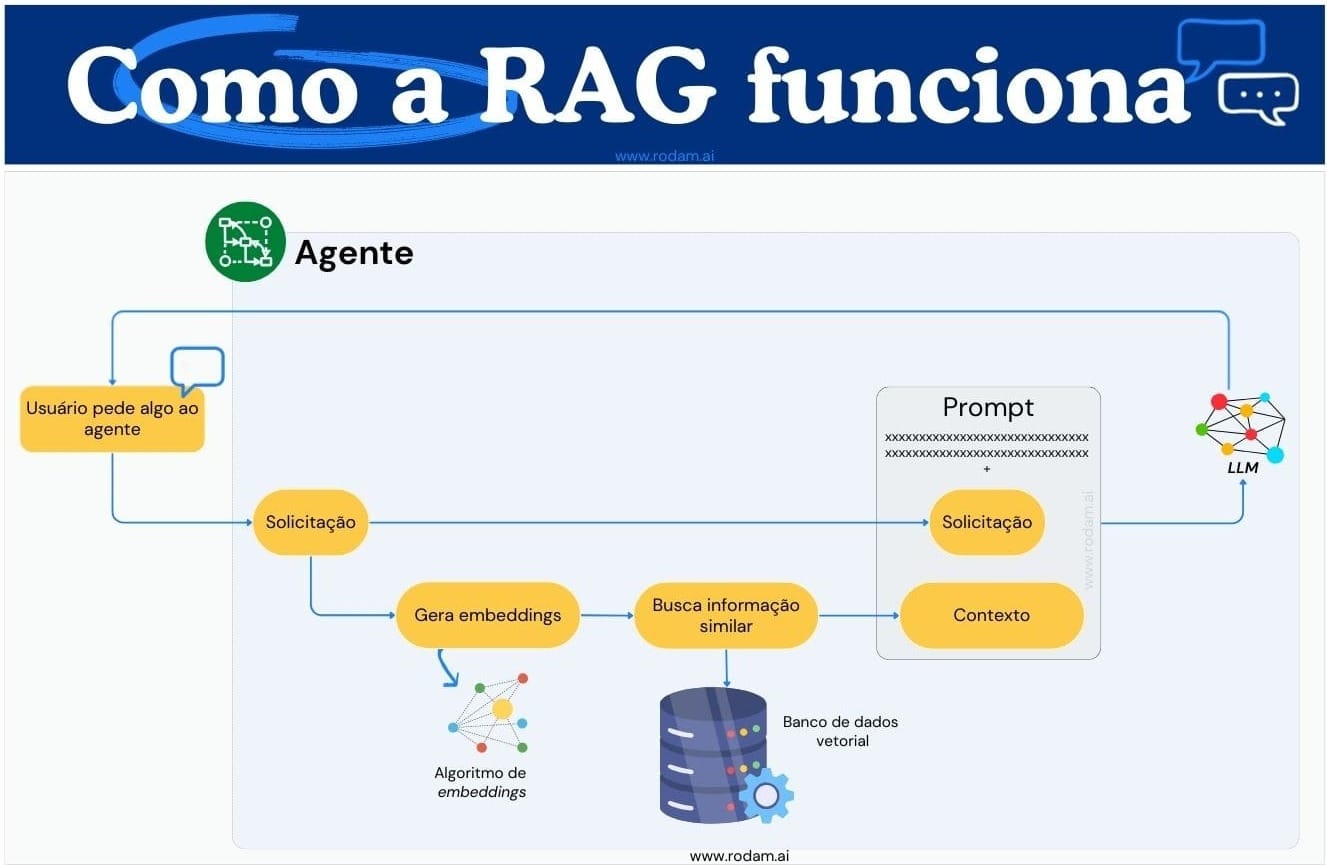
Muito simples né? Mas não se engane, há diversos desafios nessa implementação.
Desafios no uso da RAG
Você já deve ter percebido que há alguns desafios que devemos prestar atenção ao usarmos a RAG. Aqui vão alguns principais:
Atualização das informações
Os dados que temos na nossa empresa são atualizados constantemente, então é necessário criarmos um processo de curadoria das informações que alimentam o banco de dados que fornece informações ao agente, caso contrário ele fornecerá informações desatualizadas e de nada adiantará todo esse esforço colocado nessa arquitetura.
Divisão da informação
Não entrei em muitos detalhes aqui, pois não é objetivo deste artigo, mas no momento de estruturarmos o conhecimento para a indexação na base de dados, pode ser necessário "quebrarmos" esse conteúdo em pedaços menores, isso pode acontecer quando temos conteúdos muito extensos dentro de um mesmo documento ou referente a um mesmo assunto e os LLMs possuem limites para seus prompts, portanto, precisamos além de passar um contexto para o modelo, esse contexto deve ser otimizado também em tamanho de texto. Farei um post específico apenas sobre esse assunto.
Diferentes contextos
Outro ponto que pode ser desafiador é a junção de diferentes contextos dentro de um mesmo agente, por exemplo: podemos indexar contratos, documentos de TI, documentos comerciais e documentos de RH. Quando um usuário perguntar algo, por exemplo: Como foi a última proposta enviada ao fulano de tal?
A pesquisa por similaridade pode retornar algumas possibilidades aqui: uma proposta comercial enviada a alguém, uma proposta de trabalho enviada a um candidato ou ainda que uma determinada proposta foi enviada por e-mail. Percebe o problema? Dependendo do retorno recebido, o LLM irá devolver uma resposta ao usuário completamente sem sentido, que nos fará pensar que o modelo "alucinou", mas na verdade ele simplesmente trabalhou com a informação que recebeu.
O uso da RAG traz ainda outros desafios, que tratarei em um próximo artigo, como por exemplo, escalabilidade dos agentes, qualidade dos dados, como tratar privacidade, controle de acesso entre outros.
Hoje vimos que implementar um assistente de IA na sua empresa ou vida pessoal já é uma realidade. Compartilhe sua experiência e ajude outros entusiastas a explorar essa tecnologia com confiança. Envie suas dúvidas, comentários e histórias!
E não se esqueça de espalhar o conhecimento. Compartilhe esta postagem para ajudar outros a criar um copiloto de IA. Inovação tecnológica é um esforço coletivo!



