O básico sobre engenharia de dados


Todos os sistemas na área de TI manipulam dados. Alguns poucos, outros muitos, mas todos eles processam dados que, são transformados em informações. Ao longo dos anos os sistemas foram evoluindo, novas tecnologias surgindo, mas essa dinâmica de manipulação de dados sempre aconteceu e ouso dizer que sempre acontecerá. O que mudou foram as tecnologias e metodologias aplicadas nesse processo. Meu objetivo é falar do processo e metodologias em si e não de produtos específicos.
Com o crescimento do uso de dados pelas organizações e com a popularização do Bigdata a disciplina de engenharia de dados saiu do colo dos DBA’s e administradores de sistemas e passou a permear praticamente toda a área de tecnologia. Aliás, o tema data-driven não é algo apenas de tecnologia e faz parte de toda a organização, mas essa é outra conversa.
Podemos dizer que o “coração” da engenharia de dados é o pipeline de dados. Que nada mais é que um conjunto de operações sequenciais que movimentam dados, geralmente envolvendo transformações e consolidações para diversos propósitos, mas principalmente para fins analíticos.
No geral, ele contém as seguintes etapas:
- Coleta de Dados: A primeira etapa é a aquisição de dados. Por menor que seja a organização, ela terá diferentes fontes de dados, que podem incluir bancos de dados, sistemas de arquivos, fluxos em tempo real, APIs ou outras. Ex.: uma loja de bairro, tem no mínimo um sistema de faturamento para emitir notas fiscais, um sistema de e-mail e às vezes um CRM, isso quando não trata essas informações em planilhas de Excel. São raros os casos em que todos esses sistemas são integrados.
- Armazenamento de Dados: Os dados coletados precisam ser armazenados em algum lugar e isso pode variar bastante, mas no geral acaba indo para um banco de dados, um sistema de arquivos ou algum sistema especialista nesse tipo de armazenamento, como um data warehouse ou data lake.
- Limpeza e Preparação de Dados: Cada sistema trata seus dados de uma maneira, seja pela natureza da informação, pelo sistema de persistência dos dados que ele utiliza ou qualquer outra questão. Esta etapa envolve a limpeza de dados para remover erros ou inconsistências e a preparação dos dados para análise, o que pode incluir transformação, normalização e enriquecimento de dados. Ex.: um cenário comum em empresas de todos os tamanhos é o uso de sistemas especialistas para cada função, como um CRM para gerenciar o cadastro dos clientes, um sistema de faturamento para controlar a emissão de notas fiscais, um sistema para loja virtual, outro sistema para gestão de pessoas e por aí vai. Portanto, se eu quero ter uma visão do que meus clientes consomem nas lojas físicas e no comércio eletrônico de forma integrada e ainda saber quais os produtos têm mais aceite para cada público e qual vendedor é mais efetivo nas abordagens de venda, eu preciso juntar a informação dessas diversas fontes de dados. Para isso é preciso padronizar formatação de datas, de códigos de produtos, clientes, funcionários e diversos outros atributos para ter uma informação confiável. Entende o desafio dessa etapa? Afinal, cada sistema tem sua forma de gerenciar os dados e mesmo que cada um deles forneça relatórios, a análise só ficará completa com as informações vindas dos outros sistemas.
- Processamento e Transformação de Dados: uma vez que os dados são limpos e padronizados eles precisam estar num formato adequado para análise, em alguns casos os dados são encaminhados para um banco de dados ou armazenados em algum formato de arquivo especializado como: CSV, JSON, Avro, Parquet, Delta entre outros. Esses formatos possuem suas vantagens e desvantagens, mas o objetivo aqui é entendermos o processo, depois falaremos mais deles.
- Organização de Dados: organizar os dados de forma que possam ser facilmente acessados, consultados e analisados por ferramentas de análise de dados e usuários finais. Ex.: uma abordagem comum é organizar os dados em camadas e cada camada possui os dados organizados de forma mais refinada que a camada anterior.
- Disponibilização dos dados: Após a organização, os dados devem estar disponíveis para análise. Esta análise pode ser realizada por cientistas de dados e analistas que procuram insights ou padrões, portanto há muita manipulação de dados nessa área, ou seja, há muitas consultas e a disponibilização dos dados deve estar em um local que preveja esse consumo concorrente.
- Monitoramento e Manutenção de Dados: É fundamental monitorar o desempenho dos sistemas de dados e realizar a manutenção para garantir a integridade, segurança e disponibilidade dos dados. Todo o processo que falamos até aqui é cíclico e em constante atualização, pois os sistemas que coletamos as informações continuam a gerar informações e o maior desafio é que esses mesmos sistemas também sofrem atualizações que podem "quebrar" os pipelines existentes. Portanto, o monitoramento da execução do pipeline, assim como sua manutenção, é algo tão importante quanto o desenvolvimento de novos pipelines.
- Governança e Segurança de Dados: Estabelecer políticas e práticas para gerenciar a acessibilidade, privacidade, segurança e conformidade dos dados nos sistemas de origem é algo comum, ou pelo menos deveria ser. Da mesma maneira, essas preocupações devem se estender ao longo da movimentação de dados, ou seja, durante todas as etapas dos pipelines essas políticas e restrições devem ser observadas e aplicadas. Felizmente, há mecanismos e práticas que nos ajudam a manter esse controles operacionais ativos em pipelines de dados bem desenhados e implementados.
Cada uma dessas etapas é essencial e pode ser considerada "principal" dependendo do contexto específico e dos objetivos do projeto. No entanto, se tivesse que escolher um processo que é frequentemente o coração da engenharia de dados, seria o processamento e transformação de dados, já que converter dados brutos em um formato útil para análise é fundamental para qualquer esforço de dados.
Em ambientes de data warehouse é muito comum utilizarmos o termo ETL, sigla para Extract, Transform e Load, onde a carga de trabalho envolve processamento de lotes de dados atualizados em intervalos regulares — por exemplo, diariamente, semanal ou mensalmente. No entanto, à medida que a necessidade de análise em tempo real cresceu, surgiram padrões como o ELT Extract, Load e Transform, onde os dados são primeiramente carregados e depois transformados dentro do data warehouse, aproveitando a potência de processamento destes sistemas modernos.
Além disso, muitos pipelines de dados modernos utilizam técnicas de streaming de dados, que permitem que os dados sejam processados quase em tempo real, sem a necessidade de esperar por um lote completo de dados para iniciar o processamento.
Para entendermos o processo na prática, quando um usuário recebe uma planilha e transfere de forma manual parte das informações para um sistema, podemos dizer que ele está fazendo um processo de ETL rudimentar e manual, posto que ele está extraindo uma informação, filtrando ou "transformando-a", e carregando para um destino diferente do original. Isso funciona em muitos casos, mas para grandes demandas essas atividades devem automatizados, passíveis de auditoria, rápido e sem margens para erro humano.
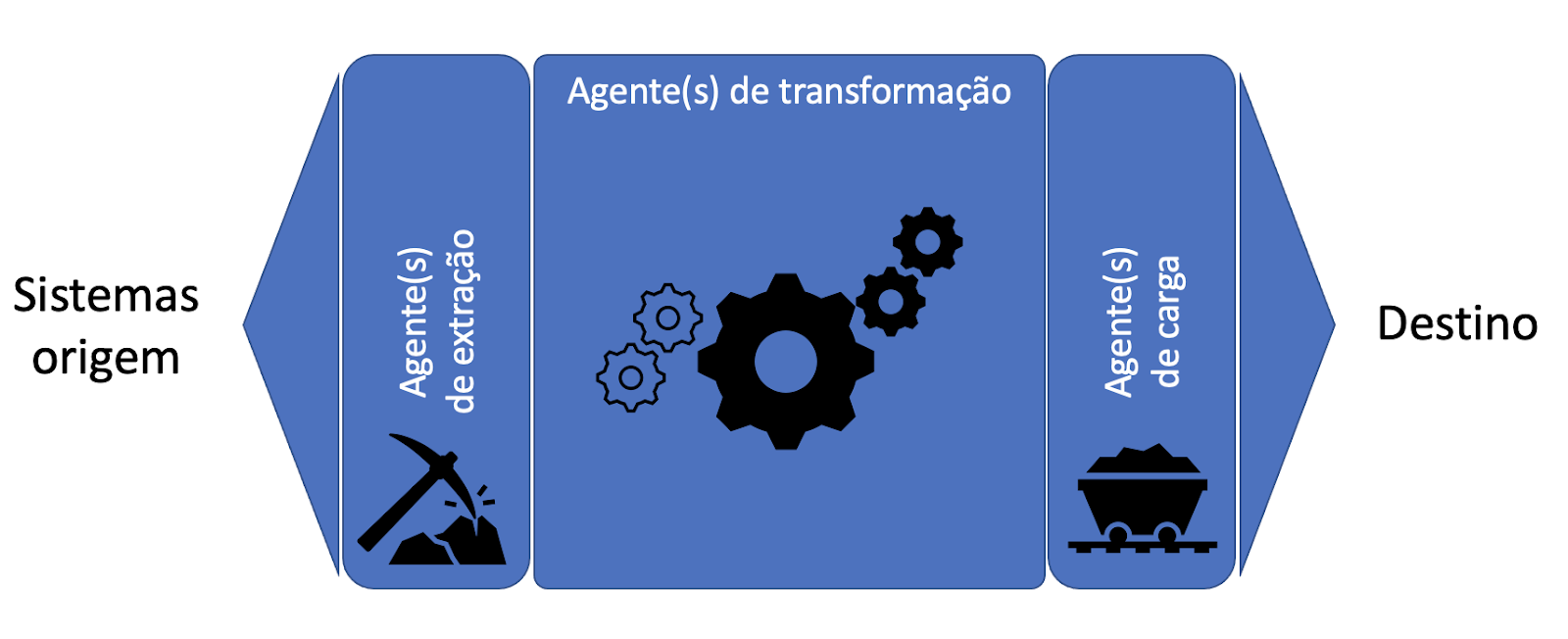
Apesar de aparentemente simples, esse processo pode se tornar uma verdadeira dor de cabeça, deve contar com o apoio de profissionais experientes, no mínimo, para sua revisão e otimização, além é claro, da gestão de projetos para garantir o correto gerenciamento dos recursos durante a elaboração/construção dos fluxos e uma gestão de operação para o devido monitoramento e manutenção em produção.

A imagem anterior demonstra, uma visão geral de um fluxo de dados tradicional, representando os sistemas de origem, onde a extração busca os dados e inicia o fluxo, algumas atividades realizadas durante a transformação, o envio ao destino e a disponibilização para os consumidores dos dados. Esses agentes podem ser scripts desenvolvidos para cada finalidade, ferramentas de mercado especialista nessas atividades ou ainda uma combinação de ambos.
Como dito anteriormente, todas as etapas desse fluxo possuem seus desafios e também já possuem diversos padrões de soluções para resolvê-los. Existem inúmeras ferramentas no mercado para endereçar cada um deles e cabe ao engenheiro de dados e a equipe do projeto identificar qual é a mais adequada para o seu cenário.
Esse é um assunto bem extenso e com muitas particularidades e ramificações que pretendo abordar em outros artigos.
E aí, na sua visão, qual o maior desafio da engenharia de dados na sua organização?



