Porque o tamanho importa: LLM vs. SLM
Descubra como o tamanho dos modelos de linguagem influenciam na qualidade, custo e velocidade de respostas.


Nos últimos semestres, os modelos de linguagem de grande escala (Large Language Models - LLMs) tornaram-se protagonistas no campo da inteligência artificial, revolucionando áreas como processamento de linguagem natural (NLP, sigla em inglês), geração de texto, tradução automática e muito mais. Modelos como GPT-4 e outros de grande porte estão na vanguarda dessa transformação, produzindo respostas incrivelmente detalhadas e contextualmente precisas.
No entanto, essa ascensão dos LLMs levanta uma questão importante: o tamanho de um modelo de linguagem realmente importa? E como ele influencia fatores como a qualidade das respostas, o tempo de treinamento, o poder computacional exigido e, claro, os custos? Enquanto LLMs são reconhecidos por sua capacidade de gerar conteúdo sofisticado, modelos menores, os chamados Small Language Models - SLMs, têm seus próprios méritos, sendo mais eficientes e acessíveis para diversas aplicações.
Neste artigo, pretendo comparar essas duas categorias de modelos em algumas dimensões essenciais, como: tamanho, poder computacional, custos, desempenho entre outras. O objetivo é entender como o tamanho impacta diretamente na aplicação desses modelos, ajudando a identificar quando um modelo maior ou menor pode ser a melhor escolha.
O Tamanho do Modelo
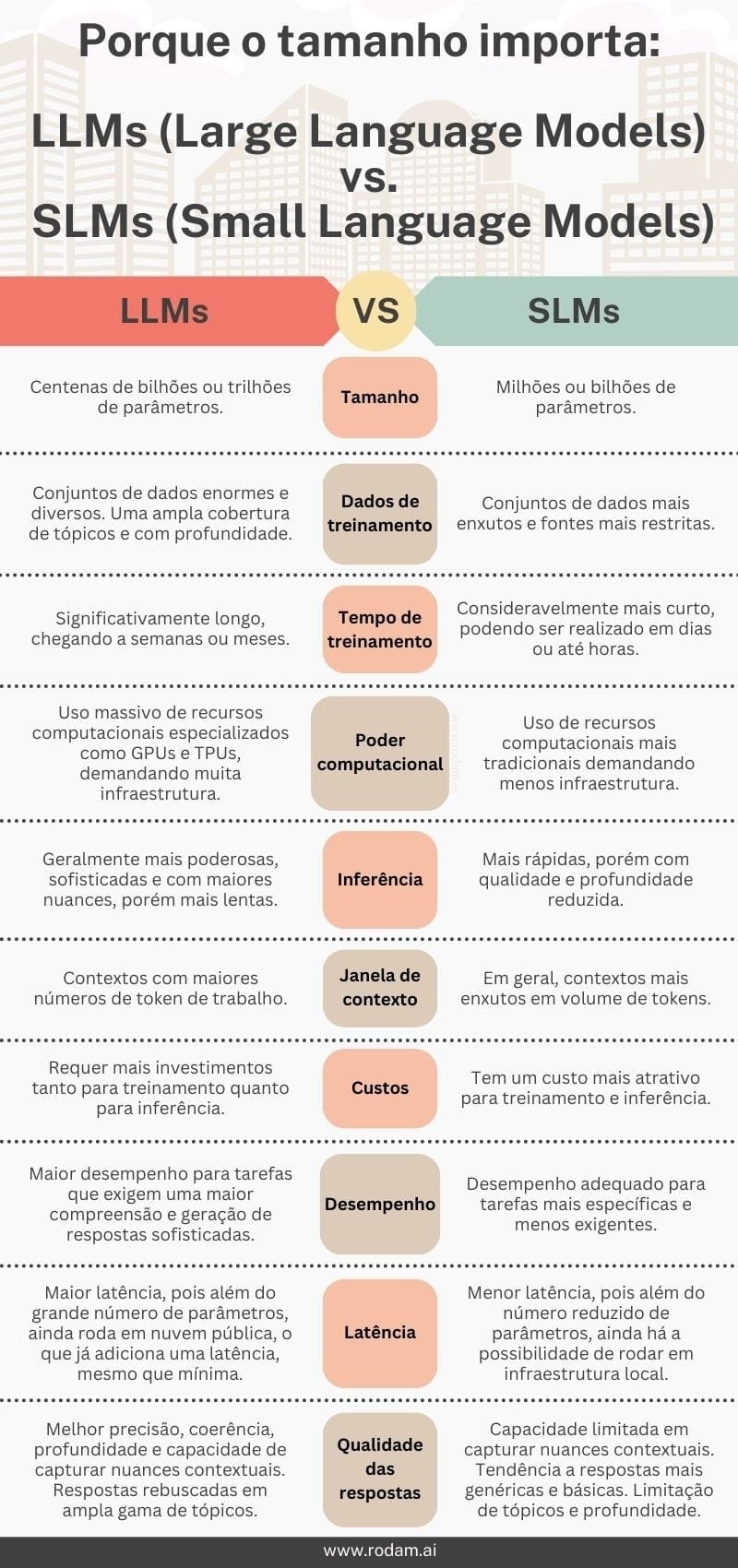
O tamanho de um modelo de linguagem é geralmente medido pelo número de parâmetros que ele contém. Parâmetros são os elementos internos ajustáveis que determinam como o modelo processa os dados e gera previsões. Nos LLMs, esses parâmetros podem chegar a centenas de bilhões, como no GPT-4, que possui trilhões de conexões. Já nos SLMs, o número de parâmetros é significativamente menor, variando entre milhões ou algumas centenas de milhões.
Esse aumento exponencial no número de parâmetros dos LLMs permite uma maior capacidade de aprendizado e generalização. Modelos maiores podem processar mais nuances contextuais e linguísticas, sendo capazes de gerar respostas mais sofisticadas e complexas. Por outro lado, SLMs, com menos parâmetros, tendem a ser mais rápidos e leves, mas com limitações no entendimento e na geração de respostas mais detalhadas.
Essa diferença de tamanho também influencia diretamente nas demais características que veremos a seguir.
Exemplos de LLMs: GPT, PaLM, BERT, Claude, Falcon, Cohere, Gemini, LlaMA & Orca. Exemplos de SMLs: Phi-3, GPT-4o mini, Gemma, Mistral Small, OpenELM
Dados de treinamento
Um dos principais fatores de comparação entre os tipos de modelos são os dados de treinamento, tanto a quantidade quanto a qualidade desses dados são fatores críticos para o seu desempenho. Os LLMs, por conta de seu tamanho, demandam quantidades massivas de dados para um treinamento eficaz. Esses modelos precisam ser expostos a bilhões ou até trilhões de tokens para aprender as nuances da linguagem humana. Em muitos casos, são treinados com textos gigantescos que incluem dados de diversas fontes, como livros, artigos científicos, websites e redes sociais, garantindo uma cobertura ampla de tópicos e estilos de escrita.
Já os SLMs, por sua natureza menos complexa, podem ser treinados com conjuntos de dados menores. Isso pode ser uma vantagem em cenários onde a disponibilidade de dados é limitada ou quando se busca reduzir custos e tempo de treinamento. No entanto, essa limitação no volume de dados pode impactar a capacidade do modelo de gerar respostas ricas em detalhes ou lidar com contextos mais complexos. Mas não se engane, isso não quer dizer que os SLMs precisam de poucos dados para treinamento, apenas que precisam de um volume bem inferior aos LLMs.
Outro ponto importante é a diversidade dos dados. LLMs, ao serem treinados com vastas e variadas fontes, tendem a apresentar um maior entendimento contextual e melhor adaptação a diferentes domínios e linguagens. Isso os torna extremamente versáteis em aplicações que exigem alta generalização. Por outro lado, os SLMs, dependendo de seu conjunto de dados mais restrito, podem se especializar em tarefas mais específicas, oferecendo um desempenho adequado dentro de certos domínios, mas com menor capacidade de generalização.
Portanto, enquanto os LLMs ganham em cenários onde o acesso a grandes quantidades de dados é viável e necessário, os SLMs têm seu espaço em contextos onde conjuntos de dados menores e mais especializados são suficientes para alcançar o objetivo desejado. Esse parâmetro é importante pois é com base nele que o modelo terá seu comportamento durante a fase de inferência.
Tempo de treinamento
No momento de treinamento do modelo, além da questão dos dados o tamanho do modelo influencia diretamente no tempo necessário para essa tarefa ser realizada. Diferentemente do item anterior, avaliar o tempo de treinamento, não faz muito sentido para a maioria dos usuários dos modelo, exceto se você produz tecnologia e customiza diretamente esses modelos, uma abordagem muito pouco efetiva para mais de 90% dos casos.
Nos LLMs, o tempo de treinamento pode ser significativamente longo. Modelos como o GPT-4 podem levar semanas ou até meses para serem treinados em clusters de GPUs ou TPUs de alta performance, consumindo quantidades massivas de energia e recursos computacionais.
Em comparação, SLMs demandam muito menos tempo para treinamento. O processo de treinamento é consideravelmente mais rápido, podendo ser realizado em dias ou até horas, dependendo da infraestrutura e do tamanho do modelo. Isso torna os SLMs uma escolha mais prática em ambientes onde a rapidez de desenvolvimento é crucial, ou onde há restrições de tempo e recursos.
Outro aspecto importante é a fase de ajuste fino (fine-tuning), que pode ser especialmente vantajosa para SLMs. Devido ao menor número de parâmetros, SLMs podem ser ajustados rapidamente para tarefas específicas sem a necessidade de treinamento completo do zero. Em contraste, o fine-tuning de LLMs pode ser um processo mais lento, mesmo que ofereça uma precisão maior para casos de uso complexos.
Vale destacar que o tempo de treinamento impacta o ciclo de desenvolvimento da IA e organizações que precisam lançar produtos rapidamente podem preferir SLMs pela rapidez com que esses modelos podem ser desenvolvidos e testados. Já para empresas que buscam modelos com capacidades mais avançadas e não têm tanta urgência no tempo de entrega, os LLMs são mais indicados, apesar do tempo mais longo para seu desenvolvimento.
Em resumo, o tempo de treinamento é um fator crítico na escolha entre LLMs e SLMs. Enquanto os LLMs demandam mais tempo para essa tarefa os SLMs são mais ágeis, o que os torna mais viáveis em ambientes com essa restrição. Apesar de ser uma dimensão de avaliação que não faz muito sentido para a maioria dos usuários desses modelos, já que a maior parte dos casos fazem uso dos modelos já treinados.
Poder Computacional
A quantidade de parâmetros que o modelo possui determina o poder computacional necessário para treiná-lo e operá-lo, sendo essa característica uma das maiores diferenças entre LLMs e SLMs. Os LLMs, com bilhões ou trilhões de parâmetros, exigem uma infraestrutura computacional massiva. Para treinar um LLM como o GPT-4, por exemplo, são necessárias centenas ou até milhares de GPUs ou TPUs trabalhando em paralelo por longos períodos.
Além disso, a demanda computacional não se limita apenas à fase de treinamento. Durante a inferência — ou seja, o uso do modelo para gerar respostas — LLMs continuam a exigir uma quantidade considerável de recursos. A alta complexidade dos modelos e o número de parâmetros resultam em maiores necessidades de memória e processamento, o que pode aumentar a latência. Isso é especialmente relevante em cenários onde a inferência precisa ser feita em tempo real ou em larga escala.
Por outro lado, os SLMs são muito mais acessíveis em termos de poder computacional. Como possuem menos parâmetros, podem ser treinados e operados em máquinas menos poderosas, até mesmo em computadores pessoais ou servidores menores. Esse consumo reduzido de recursos torna os SLMs uma opção ideal para organizações com restrições de infraestrutura, permitindo que sejam treinados e implantados de forma mais ágil.
Além disso, SLMs podem ser executados de forma mais eficiente em dispositivos de borda (edge devices) ou sistemas embarcados, onde o poder computacional é limitado. Isso amplia o alcance de suas aplicações, especialmente em áreas como IoT (Internet das Coisas) e mobile computing, onde modelos menores são essenciais para rodar localmente sem depender de grandes centros de dados.
Em resumo, a escolha entre LLMs e SLMs envolve considerar o equilíbrio entre o poder computacional necessário e os benefícios obtidos. Enquanto LLMs oferecem resultados mais robustos e sofisticados, exigem uma demanda computacional muito superior aos SLMs, que por outro lado, podem ser treinados e operados com muito menos recursos, sendo mais acessíveis e viáveis para uma ampla gama de aplicações.
Inferência
A inferência refere-se ao processo de utilização de um modelo já treinado para fazer previsões ou gerar respostas e esse processo varia significativamente entre os dois tipos de modelo.
Nos LLMs, a inferência geralmente é mais lenta e exige mais poder computacional. Isso acontece porque, com um número muito maior de parâmetros, o modelo precisa de mais tempo e recursos para processar uma solicitação e gerar uma resposta. Dependendo da complexidade do modelo e da tarefa, a inferência em tempo real pode ser desafiadora, especialmente em aplicações que demandam respostas rápidas e frequentes, como chatbots, assistentes virtuais e sistemas de atendimento ao cliente. Por essa razão, muitas vezes a inferência de LLMs é feita em grandes servidores ou em ambientes em nuvem.
Em contrapartida, os SLMs, por serem mais leves, oferecem inferências muito mais rápidas e com menor consumo de recursos, o que é uma vantagem significativa em ambientes onde a latência baixa é crítica, como em sistemas embarcados, aplicativos móveis ou dispositivos de IoT. A rapidez com que os SLMs podem processar e retornar resultados torna-os mais eficientes em cenários que exigem velocidade, mesmo que, em alguns casos, isso signifique uma redução na qualidade ou na profundidade das respostas.
Em resumo, enquanto LLMs oferecem inferências mais poderosas e detalhadas. Por outro lado, SLMs são uma escolha prática para aplicações com foco em baixa latência, mesmo que comprometam um pouco a profundidade e qualidade das respostas.
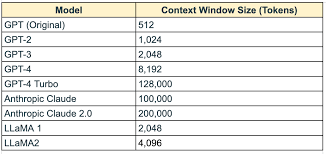
Janela de contexto
Antes de compararmos os tipos de modelo por essa característica, precisamos entender o que ela significa. A janela de contexto em modelos de linguagem refere-se à quantidade de tokens que o modelo pode "ler" e processar ao mesmo tempo para gerar uma resposta ou fazer previsões. Em outras palavras, é a quantidade máxima de texto que o modelo consegue considerar de uma vez para compreender e responder adequadamente a uma pergunta, comando ou sequência de texto.
Ela limita o número de tokens que o modelo pode considerar em uma única operação de inferência. Por exemplo, se a janela de contexto de um modelo é de 4.000 tokens, ele só poderá levar em conta esses 4.000 tokens anteriores quando gerar uma resposta. Se o texto fornecido for maior do que isso, o modelo "esquece" as partes mais antigas do texto e foca apenas nos tokens mais recentes, dentro do limite.
Modelos com janelas de contexto menores podem ter dificuldades em lidar com longos textos de forma completa e coerente. Em situações onde se precisa de um entendimento global de um texto extenso, como em artigos longos ou documentos técnicos, é preferível uma janela de contexto maior.
Se a janela de contexto não for grande o suficiente, partes importantes da conversa ou do texto original podem ser perdidas, levando a respostas menos precisas ou incoerentes.
Modelos mais recentes, como o GPT-4, tendem a ter janelas de contexto maiores, o que melhora sua capacidade de lidar com textos longos, manter a coerência em conversas estendidas e fornecer respostas mais completas.
Ou seja, a janela de contexto determina a quantidade de texto que o modelo consegue "lembrar" de uma vez e usar para gerar suas respostas, influenciando diretamente a qualidade e a relevância das respostas em textos longos ou interações contínuas.
E advinha? Os LLMs em geral possuem janelas de contexto mais extensas que os SLMs, mas cada versão de modelo tem um tamanho e ao longo do tempo esses contextos tem se tornado cada vez maiores com o lançamento de novos modelos.
Custos
Os custos associados ao desenvolvimento e operação de modelos de linguagem variam drasticamente entre LLMs e SLMs. O custo total pode ser dividido em duas categorias principais: custos de treinamento e custos de inferência. Lembrando que, assim como no caso do tempo de treinamento, os custos de treinamento só fazem sentido para organizações que passam por essa fase.
Nos LLMs, os custos de treinamento são substancialmente altos devido à quantidade massiva de dados necessários, ao número elevado de parâmetros e principalmente à infraestrutura computacional exigida. Treinar um LLM pode custar milhões de dólares, dependendo do modelo e da complexidade do hardware envolvido. O processo de treinamento geralmente requer clusters de GPUs ou TPUs de última geração, além de semanas ou meses de processamento, o que também resulta em um consumo elevado de energia. Além disso, o armazenamento dos grandes volumes de dados necessários para treinar LLMs é outro fator que contribui para o aumento dos custos.
Os custos de inferência em LLMs também são consideráveis. Mesmo após o modelo estar treinado, o alto número de parâmetros implica em um maior uso de memória e poder computacional durante a operação, o que se traduz em maior custo por solicitação. Isso torna os LLMs caros para aplicações em larga escala, especialmente quando há muitas inferências em tempo real ou quando é necessário executar o modelo em ambientes com recursos limitados.
Por outro lado, os SLMs são muito mais econômicos tanto em termos de treinamento quanto de inferência. Como esses modelos têm um número menor de parâmetros e podem ser treinados com conjuntos de dados menores, o custo de treinamento é significativamente reduzido. SLMs podem ser treinados em hardware menos sofisticado, como servidores convencionais ou até mesmo em máquinas locais, o que também reduz o consumo de energia e os custos associados à infraestrutura.
Em relação à inferência, os SLMs são mais baratos para operar devido à sua menor exigência de poder computacional. Com menos parâmetros e menor consumo de memória, eles permitem que inferências sejam feitas de maneira rápida e eficiente, tornando-os ideais para aplicações em que o custo por solicitação precisa ser mantido baixo, como em serviços que atendem um grande número de usuários simultâneos.
Em resumo, a escolha entre LLMs e SLMs em termos de custos depende do orçamento disponível e das necessidades da aplicação. LLMs exigem um investimento maior, enquando os SLMs, por outro lado, são mais acessíveis em termos financeiros, representando uma solução para muitas empresas que possuem restrições orcamentárias.
Desempenho
O desempenho de um modelo de linguagem é um fator crucial para sua eficácia em diversas aplicações. Ele pode ser avaliado de várias formas, como a precisão das respostas, a capacidade de adaptação a diferentes contextos, e a eficiência com a qual o modelo processa as solicitações. Tanto LLMs quanto SLMs têm suas particularidades em termos de desempenho.
Os LLMs, com seu grande número de parâmetros e vasto treinamento, geralmente oferecem um desempenho superior em termos de compreensão contextual e geração de respostas mais coerentes e detalhadas. Eles têm a capacidade de processar frases complexas, identificar nuances linguísticas e adaptar-se a uma ampla gama de tópicos. Isso os torna mais eficazes em tarefas que exigem um alto nível de sofisticação, como redação criativa, tradução automática avançada e análise semântica profunda. Em benchmarks e testes de linguagem natural, os LLMs geralmente superam os SLMs em métricas de precisão e fluência.
Por outro lado, os SLMs, embora mais limitados em termos de complexidade, podem oferecer um desempenho adequado em tarefas mais específicas e menos exigentes. Eles são especialmente úteis em situações onde a simplicidade da tarefa ou a especialização em um domínio específico é mais importante do que a abrangência e a sofisticação. Em muitas aplicações práticas, como classificação de texto, análise de sentimentos ou extração de informações, os SLMs podem atingir níveis de desempenho aceitáveis.
No entanto, é importante destacar que o desempenho dos LLMs pode ser impactado negativamente pela latência — o tempo que leva para gerar uma resposta. Além disso, os LLMs, embora mais precisos em muitos aspectos, podem ser mais propensos a gerar respostas excessivamente elaboradas ou não diretamente relacionadas à pergunta original.
Já os SLMs, com sua estrutura mais enxuta, têm uma resposta muito mais ágil. O que os torna ideais para aplicações que exigem baixa latência, como assistentes de voz, sistemas de recomendação e serviços que envolvem interação rápida com o usuário. No entanto, essa agilidade pode vir às custas de uma menor precisão em contextos complexos ou de maior dificuldade em lidar com nuances linguísticas.
Em resumo, a escolha entre LLMs e SLMs em termos de desempenho, depende da necessidade de complexidade e rapidez do resultado da tarefa solicitada. Enquanto os LLMs oferecem um desempenho superior em tarefas complexas e contextualmente ricas, os SLMs se destacam em cenários que demandam respostas rápidas e específicas.
Latência
A latência é o tempo que um modelo leva para processar uma solicitação e retornar uma resposta. Quando se trata de LLMs e SLMs, a latência é uma das principais diferenças operacionais, especialmente em aplicações que requerem respostas em tempo real.
Nos LLMs, a latência tende a ser maior devido ao número elevado de parâmetros e a complexidade do modelo. Quando uma solicitação é feita, o modelo precisa processar uma quantidade significativa de dados internos, o que aumenta o tempo de resposta. Isso pode ser um problema em aplicações que dependem de interações rápidas, como assistentes virtuais, chatbots e sistemas de atendimento ao cliente. Quanto maior o modelo, mais tempo ele levará para gerar uma resposta, o que pode impactar a experiência do usuário.
Por outro lado, os SLMs, por serem menores e menos complexos, apresentam uma latência significativamente mais baixa. Com menos parâmetros e cálculos a serem feitos, esses modelos conseguem processar solicitações de forma muito mais rápida, tornando-os ideais para aplicações que exigem respostas imediatas ou em grande escala. Aplicações como recomendações de produtos, buscas rápidas, ou mesmo sistemas embarcados, se beneficiam da menor latência dos SLMs, garantindo uma experiência mais ágil para o usuário.
No entanto, essa diferença de latência traz consigo um trade-off. Enquanto os LLMs podem ser mais lentos, eles são capazes de fornecer respostas mais detalhadas e contextualmente corretas, especialmente em situações complexas. Em contrapartida, a rapidez dos SLMs pode resultar em respostas mais diretas, porém com menos nuances e precisão, especialmente quando enfrentam cenários linguísticos ou contextuais mais complicados.
Outro ponto a considerar é que, em ambientes de nuvem, a latência também depende da infraestrutura. Os LLMs geralmente são hospedados em servidores poderosos para compensar o tempo de processamento e há diversas camadas de rede entre a aplicação e o modelo em si. Já os SLMs, com suas exigências computacionais menores, podem rodar em servidores menos robustos ou até mesmo em dispositivos locais, como smartphones ou edge devices, podendo dessa forma, reduzir a latência total.
Portanto, a escolha entre LLMs e SLMs em termos de latência está ligada ao tipo de aplicação e à necessidade de equilíbrio entre a velocidade da resposta e a qualidade da inferência. Enquanto os LLMs são mais indicados para tarefas que exigem precisão e profundidade, os SLMs podem se destacar em aplicações que demandam rapidez e alta frequência de solicitações.
Qualidade das Respostas
A qualidade das respostas geradas por modelos de linguagem é uma dimensão crítica na escolha entre LLMs e SLMs. Essa qualidade pode ser medida pela precisão, coerência, profundidade e capacidade de capturar nuances contextuais em diferentes situações.
Nos LLMs, a qualidade das respostas tende a ser significativamente superior, especialmente em tarefas complexas que exigem uma compreensão profunda da linguagem natural. Como vimos anteriormente, esses modelos são treinados com uma quantidade massiva de dados e possuem bilhões de parâmetros que lhes permitem capturar intricadas relações semânticas e fornecer respostas mais contextualmente adequadas. Os LLMs são excelentes em gerar texto fluente, coeso e detalhado, sendo capazes de lidar com perguntas ambíguas, fornecer explicações extensas e ajustar suas respostas com base no contexto ou nas nuances da solicitação.
Além disso, os LLMs têm a capacidade de realizar generalização em uma ampla gama de tópicos e idiomas. Isso significa que eles podem gerar respostas satisfatórias mesmo quando enfrentam perguntas fora de seu escopo específico de treinamento, o que os torna versáteis e poderosos para aplicações que envolvem linguagem rica e diversificada, como assistentes pessoais inteligentes, criação de conteúdo, e diagnósticos avançados.
Por outro lado, os SLMs, com seu número limitado de parâmetros e dados de treinamento, geralmente fornecem respostas mais simples e diretas. Embora possam ser eficientes para tarefas específicas e de baixa complexidade, sua capacidade de captar nuances e fornecer respostas contextualmente ricas é mais limitada. Os SLMs tendem a ter um desempenho decente em cenários onde as perguntas são claras e diretas, como na categorização de textos ou na resposta a perguntas concretas. No entanto, quando se deparam com situações mais complexas ou ambiguidades linguísticas, suas respostas podem ser superficiais, inconsistentes ou imprecisas.
Outro aspecto importante a considerar é a tendência de SLMs a fornecer respostas mais genéricas e menos criativas. Enquanto um LLM pode oferecer insights ou explicações aprofundadas sobre um tema, um SLM pode simplesmente fornecer uma resposta básica sem a mesma profundidade de entendimento. Isso pode ser uma desvantagem em áreas que exigem criatividade, como escrita automatizada, marketing de conteúdo, ou interações mais avançadas com clientes.
No entanto, para muitas aplicações, a simplicidade das respostas de SLMs pode ser suficiente, especialmente em cenários onde precisão extrema e profundidade contextual não são prioritárias. Por exemplo, em aplicativos de suporte técnico, respostas rápidas e claras a perguntas comuns podem ser mais valorizadas.
Em resumo, a qualidade das respostas depende diretamente da complexidade do modelo. LLMs oferecem uma qualidade superior, com maior riqueza contextual e fluência, enquanto SLMs fornecem respostas mais simples e diretas, mas podem ser suficientes para muitos casos de uso. A escolha entre um modelo e outro deve considerar as necessidades da aplicação e a importância da profundidade e precisão nas respostas.
Quadro comparativo
Concluindo, o debate sobre o impacto do tamanho dos modelos de linguagem envolve uma análise cuidadosa das necessidades específicas do seu caso, mas uma coisa é óbvia, o tamanho deles impacta diretamente em várias características importantes que precisamos avaliar.
Enquanto os Large Language Models - LLMs oferecem respostas mais complexas e contextualizadas, seu custo elevado, latência maior e alta demanda computacional os tornam mais adequados para cenários onde a qualidade e a sofisticação das requisições e respostas são prioritárias. Por outro lado, os Small Language Models - SLMs são mais ágeis, acessíveis e eficientes em termos de recursos, sendo uma excelente escolha para tarefas mais específicas e ambientes com restrições de custo e tempo.
Ao decidir entre um LLM ou um SLM, é fundamental avaliar o equilíbrio entre os atributos que seu projeto precisa como desempenho, latência e as restrições que você possui como tempo, custo etc. sempre levando em conta o propósito da aplicação.
É muito comum o uso combinado de ambos os modelos, aproveitando o que cada um tem de melhor, afinal, quando tratamos de tecnologia, nem sempre há apenas uma única resposta correta e tudo deve ser analisado conforme o problema que estamos buscando resolver.
Quer entender melhor como esses modelos podem otimizar as operações da sua empresa ou precisa de orientação para escolher o modelo certo para suas necessidades, entre em contato! Se você acredita que esse conteúdo é interessante e pode ajudar outras pesssoas, compartilhe-o. Você pode receber esse tipo de conteúdo diretamente no seu e-mail inscrevendo-se no site. Até a próxima!



