Como a Inteligência Artificial aprende?


Essa é uma das perguntas mais comuns que me fazem quando descobrem que eu trabalho com Inteligência Artificial (IA), espero responder a essa pergunta de forma satisfatória para a maioria do público LEIGO que me acompanha, tentarei ao máximo evitar termos técnicos e ser o mais didático possível.
A IA aprende da mesma forma que nós humanos, por meio de estudo, ou seja, treinamento.
Esse treinamento, assim como nossos estudos, se dá mediante informações passadas por quem está nos ensinando ou treinando, no caso da IA. Essas informações são organizadas e preparadas para que o aprendizado ocorra da forma mais fluida possível. Para nós humanos, chamamos esse processo de educação formal, para a IA damos o nome de aprendizado de máquina supervisionado.
Mas essa não é a única forma que aprendemos, existem pessoas e IA’s que aprendem de um jeito diferente, sem a necessidade de um tutor para organizar e preparar os dados. São “autodidatas”. As IA’s que possuem essa característica, recebem o título de aprendizado de máquina não supervisionando.
Aprendizado de máquina é o termo em português, provavelmente você verá mais referências ao termo Machine Learning já que a maioria dos estudos hoje em tecnologia e nas ciências em geral convergem para essa língua.
Mas afinal, o que é uma IA?
Podemos dizer que a materialização de uma IA é um algoritmo de computador, mas não um algoritmo comum, nós o chamados de modelagem, ou modelo. Diferente de um algoritmo comum onde todas as ações já está pré-estabelecidas, um modelo possui como característica a capacidade de interpretar dados e situações aprendendo e reagindo de forma diferente em cada caso.
Vamos usar um exemplo:
Natanael é dono de um comércio e tem sofrido com diversos tipos de fraudes. Ele pediu ajuda da Isabel, uma Cientista de Dados, para saber se é possível reduzir esse problema.
A primeira coisa que Isabel faz é pegar os dados do sistema que Natanael usa em seu comércio. Nele, estão registrados todas as informações sobre as vendas e fraudes que ocorreram.
Nesse momento Isabel separa uma parte desses dados em um conjunto menor, que chama de dados para treinamento e outra parte que chama de dados para validação.
Examinando os dados, Isabel resolve iniciar seus estudos usando um algoritmo de Árvore de Decisão, existem outros, o trabalho do cientista de dados é identificar qual será o mais adequado em cada caso. Isso pode levar tempo!
Ela passa para esse algoritmo os dados de treinamento e obtém como resultado o seguinte modelo de Árvore de Decisão:
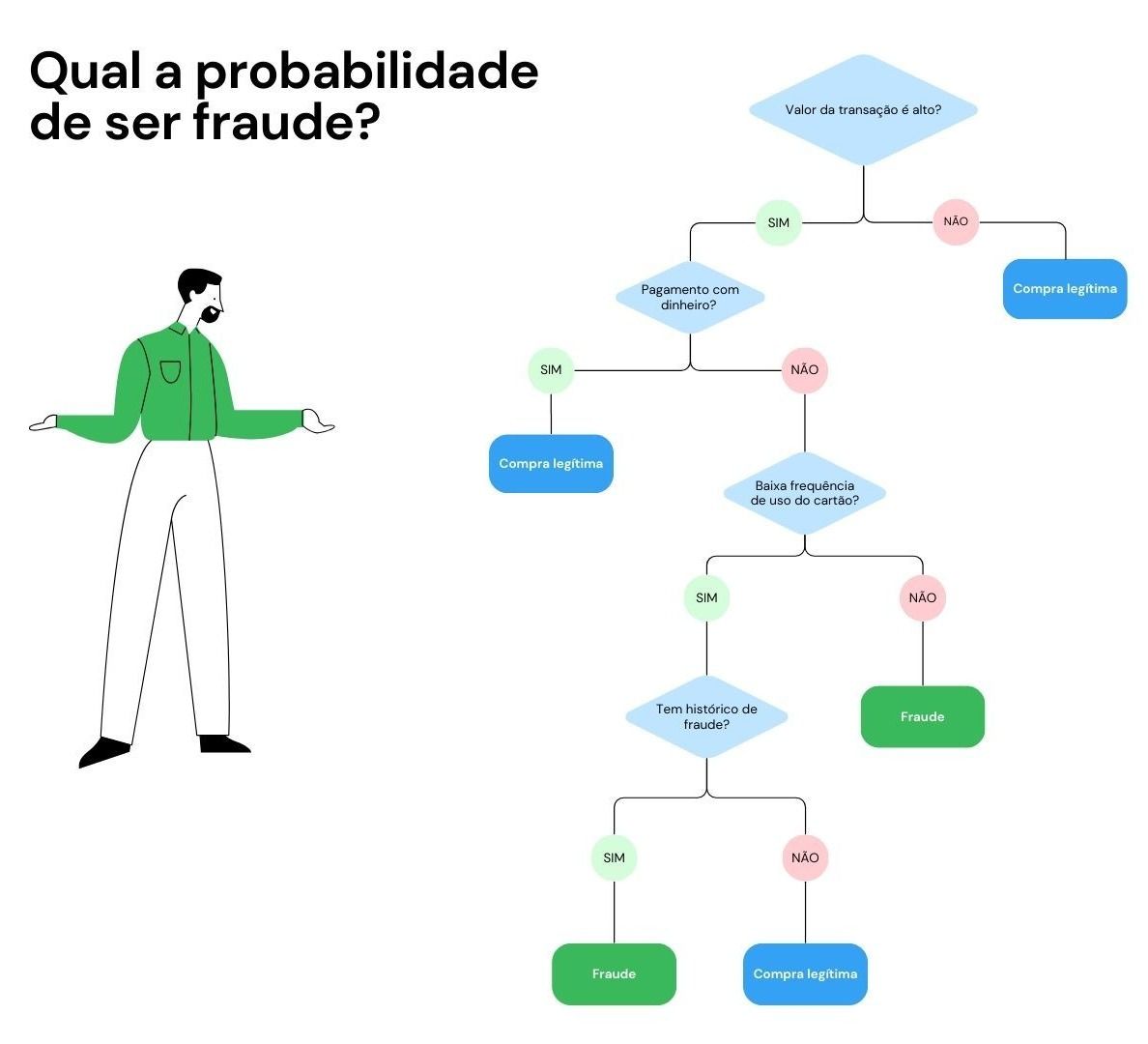
Essa árvore de decisão é um exemplo de como um modelo de Machine Learning pode ser usado para classificar transações como legítimas ou “potencialmente fraudulentas”. Cada nó da árvore representa um ponto de decisão baseado em um atributo específico dos dados de transação, e cada ramificação conduz a uma conclusão sobre a natureza da transação.
Vejamos como ela funciona:
- O nó raiz da árvore começa com a avaliação do Valor da Transação.
- Se o valor for alto, prossegue para avaliar o método de pagamento.
- Se o valor for baixo, classifica a transação como legítima.
- No caso de um valor alto, o Método de Pagamento é avaliado.
- Se for dinheiro, a transação é considerada legítima.
- Se for cartão, avalia-se a frequência de transações.
- Nos pagamentos feitos com cartão, a Frequência de Transações é considerada.
- Uma baixa frequência leva a verificar o Histórico de Fraude do usuário.
- Uma alta frequência pode indicar uma fraude.
- Se a frequência de transações for baixa, o Histórico de Fraude é verificado.
- Se houver um histórico de fraude, a transação é considerada fraudulenta.
- Caso não haja histórico de fraude, a transação é classificada como legítima.
Se você é uma pessoa atenta, deve ter percebido algumas "pontas soltas" aqui. O que é um valor de transação alto? Qual é a frequência alta de uso do cartão?
Esses valores, assim como toda a árvore, foi determinado por métodos estatísticos. Uma possibilidade, nesse caso, é que as fraudes apenas tenham ocorrido em transações com valores muito acima dos valores médios de compras, feitos por cartões com uma alta frequência de uso. E isso foi identificado apenas olhando os dados históricos de transações realizadas, e não apenas os dados de fraudes.
Após o treinamento, ou seja, uma vez convencida que o modelo está com os atributos pertinentes para conseguir altas taxas de acerto, Isabel o validará com o segundo conjunto de dados para ter certeza que não há vício no modelo e que ele pode ser usado no sistema atual para ajudar Natanael a prever futuras fraudes.
Caso a validação apresente problemas, todo o treinamento pode recomeçar ou tenha que partir para outros tipos de modelo como uma Regressão Logística, Random Forrest, Redes Neurais etc. Por isso chamamos esse processo de CIÊNCIA de dados, pois exige método.
Em que situação a validação pode dar problema?
No momento da separação dos dados entre dados de treinamento e dados de validação podemos cometer um erro perigoso. Imagine que o sistema de Natanael tenha o histórico de 5 anos de transações e Isabel tenha pego dados apenas do 2° ano para treinar seu modelo. Ela provavelmente está deixando de fora comportamentos de fraude importantes, que aparecerão na validação.
Uma forma interessante é pegar uma amostra mais diversa, tentando contemplar a sazonalidade do negócio de Natanael, com exemplos aleatórios.
Uma vez que modelo foi validado, ele deve ser colocado em produção, ou seja, antes de concluir uma transação os dados passarão pelo modelo que indicará a probabilidade da transação ser legítima ou fraudulenta antes de finalizá-la.
Acredito que nessa altura vocês já entenderam que Isabel usou um modelo de Machine Learning supervisionado, já que ela treinou e validou o modelo usando dados marcados, chamamos assim os dados que já sabemos o resultado durante a etapa de treinamento e validação. No nosso exemplo, as transações legítimas e as fraudes.
E os modelos de aprendizado não supervisionado?
Nesse exemplo do comércio de Natanel, uma situação desafiadora para usarmos algo interessante seria para segmentar os clientes. Perceba que para classificar os clientes em categorias, não temos um único atributo que pode determinar qual a categoria do cliente: valor de compras feitas, frequência de compras, tipos e produtos, etc. Esse tipo de categorização, que chamamos de clustering, ou clusterização é um exemplo perfeito de algo que um modelo não precisa de nós para treiná-lo e aprende apenas com os dados.
Mas onde o modelo é executado?
O modelo em si é um programa que pode ser integrado com qualquer outro sistema por meio de API’s ou diretamente no software que usará suas capacidades, ele geralmente usa pouco recurso computacional para responder em comparação com a capacidade exigida para sua criação, ou seja, ele é executado em um computador comum com CPU, memória RAM e HD. Exceto modelos mais sofisticados que precisam de um computador com recursos especias, como uma GPU, por exemplo.
Veja também: Inteligência Artificial - Introdução
É claro que esse assunto não se esgota aqui, não quero que a leitura se torne maçante, tem vários pontos que precisamos explorar. Fiquem atentos, logo tem mais!
Já pensou nas possibilidades que a IA pode trazer para o seu dia a dia? Quais benefícios pode extrair dela? Inscreva-se e comente ;)



