Como gerenciar grandes volumes de dados
Gerenciar grandes volumes de dados exige arquiteturas robustas como data warehouse, data lake, lakehouse, lambda e kappa. Neste artigo, apresento como essas abordagens transformam dados em insights valiosos, ajudando sua organização a crescer de forma sustentável e eficiente.


Uma das grandes dores que os times de tecnologia enfrentam é a criação de arquiteturas de sistemas robustas para suas organizações. Dentre as dificuldades que encontramos ao elaborarmos uma arquitetura de sistema incluem: entender as necessidades do negócio, escolher as tecnologias certas, garantir que todas as partes se conectem bem e possam crescer com o tempo. Além disso, é importante prever como o sistema lidará com falhas, mudanças e grandes volumes de usuários ou dados, tudo isso mantendo a segurança e a simplicidade.
Na era da informação, o volume de dados gerados diariamente pelas empresas é simplesmente colossal. Cada clique, transação e interação digital se transforma em dados, criando um grande volume de informação que pode tanto impulsionar a inovação quanto afundar uma organização despreparada. A realidade é brutal: sem uma arquitetura de sistema robusta e escalável, sua empresa pode ficar paralisada diante do caos gerado por essa infinidade de bytes.
Mas o que torna a criação de uma arquitetura de dados tão desafiadora? Não é apenas sobre escolher as ferramentas certas ou garantir a segurança; é sobre criar uma estrutura que possa crescer, se adaptar e resistir às tempestades que surgem quando os dados começam a fluir em volumes que desafiam nossa compreensão.
Neste artigo, vou apresentar algumas das arquiteturas mais comuns de big data.
Mas o que é uma arquitetura de sistema?
Uma arquitetura de sistema é como o plano ou o projeto de uma construção, mas para sistemas de tecnologia. Ela define como diferentes partes de um sistema — como software, hardware e dados — se conectam e trabalham juntas para atingir um objetivo específico. Em resumo, é a estrutura organizada que orienta como as tecnologias são combinadas para funcionar de forma eficiente.
É claro que não começamos uma arquitetura do zero. Há padrões arquiteturais que seguimos, afinal, não precisamos reinventar a roda. Esses padrões arquiteturais nos ajudam a eliminar boa parte dos problemas mais básicos logo na largada do projeto. Veremos neste artigo arquiteturas voltadas para o tratamento de grandes volumes de dados.
Arquiteturas de Bigdata
Com o crescimento exponencial dos dados gerados diariamente, a necessidade de arquiteturas robustas e escaláveis para processar, armazenar e analisar grandes volumes de informações se tornou cada vez mais comum. Porém, o conceito de big data vai além do simples armazenamento de dados, ele envolve a criação de soluções que permitem a captura, processamento e análise eficiente de dados em diferentes formatos, velocidades e volumes.
Neste contexto, surgiram diversas arquiteturas, como Data Warehouse, Data lake, Lakehouse, Lambda, Kappa e outras, cada uma com características específicas para atender a demandas empresariais distintas. Porém, irei me concentrar nas arquiteturas citadas.
Podemos separar essas arquiteturas em duas categorias, as arquiteturas com foco em armazenamento e gestão e as arquiteturas com foco em processamento de dados.
Arquiteturas de armazenamento
As arquiteturas com foco em armazenamento e gestão possuem seus componentes interligados e direcionados para esse fim, como veremos a seguir:
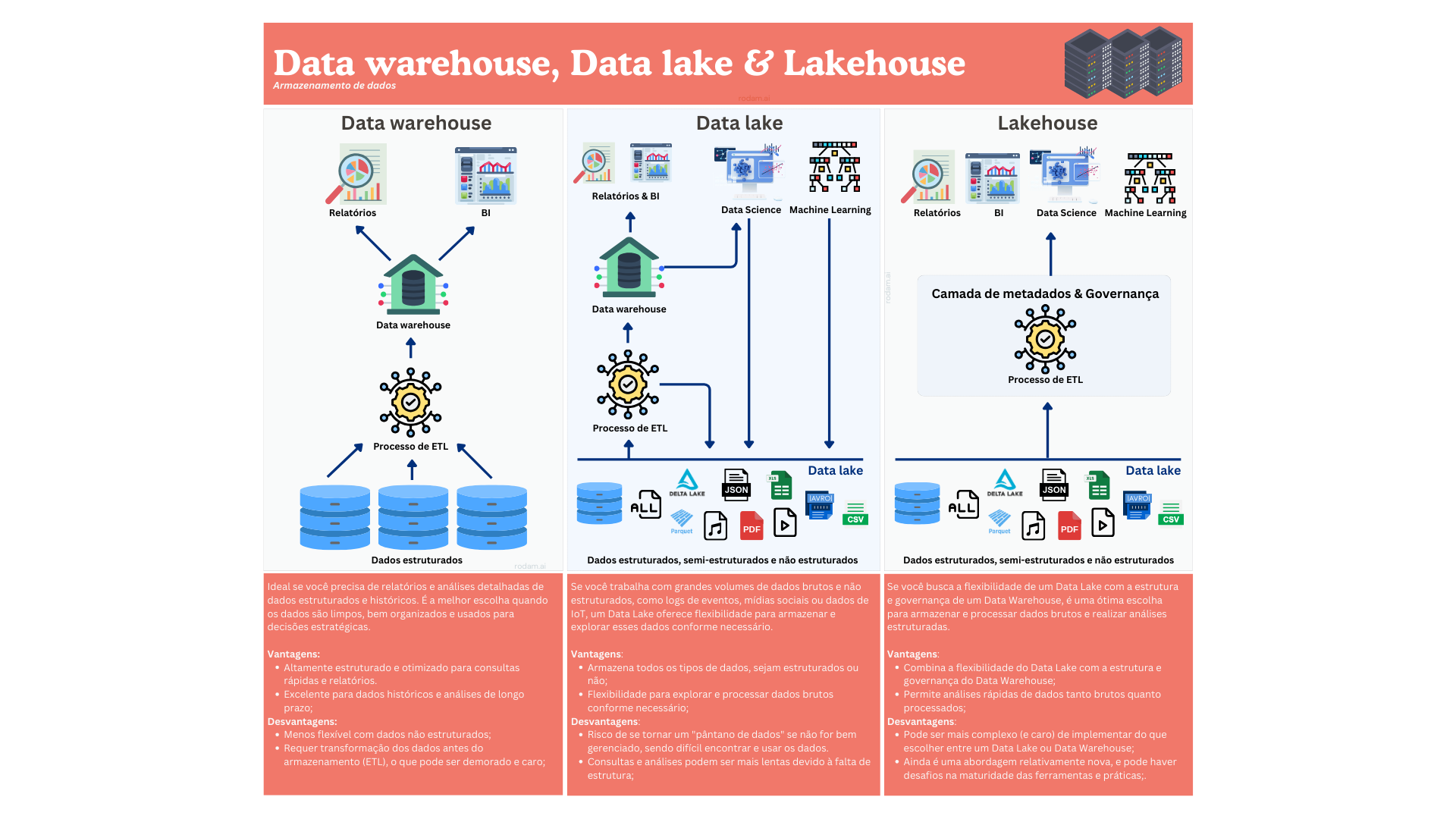
Data Warehouse
Um Data Warehouse é um repositório estruturado que armazena grandes volumes de dados já organizados e prontos para análise. Ele é como uma “biblioteca” de dados, onde as informações são processadas, categorizadas e armazenadas de maneira bem organizada, facilitando a criação de relatórios e insights. Geralmente, ele é usado para análises mais avançadas e tomadas de decisão em empresas, focando em dados estruturados e históricos.
Data lake
Um Data lake é como um grande repositório onde todos os dados, sejam estruturados ou não, são armazenados em seu formato original. Ele é flexível e permite que os dados sejam explorados e processados conforme necessário, mas exige boas práticas de organização para evitar que vire um “pântano de dados”, difícil de gerenciar.
Lakehouse
O Lakehouse combina o melhor dos Data lakes e Data Warehouses. Ele permite armazenar dados brutos, como em um Data lake, mas com a estrutura e organização de um Data Warehouse, facilitando tanto a exploração quanto a análise dos dados, mantendo desempenho e governança mais elevados.
Arquiteturas de Processamento
As arquiteturas com foco em processamento possuem seus componentes interligados e direcionados para esse fim e são combinadas com as arquiteturas de armazenamento, como veremos a seguir:
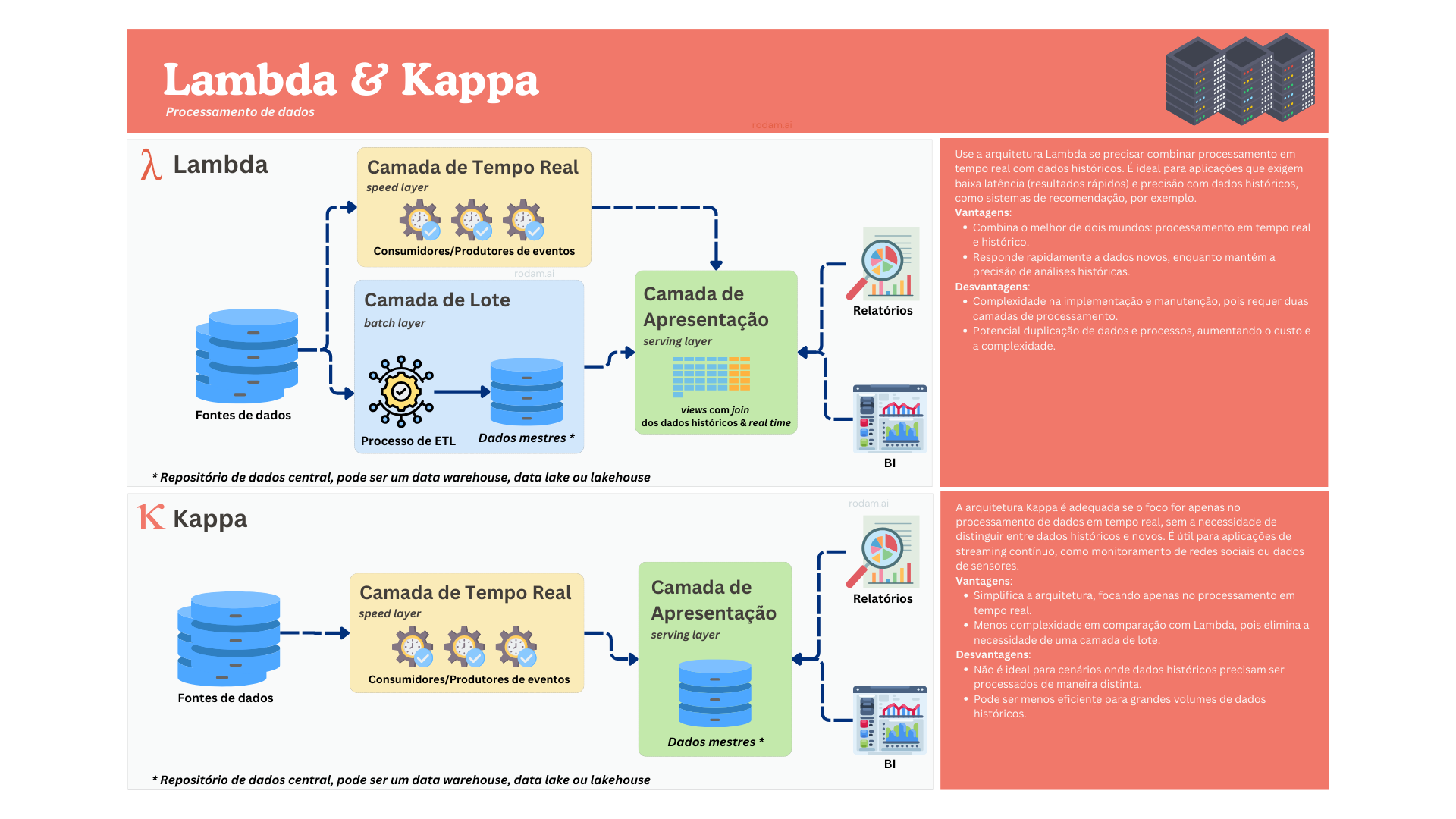
Lambda
A arquitetura Lambda combina o processamento de dados em lote (dados históricos) e em tempo real (dados que chegam na hora) para entregar resultados rápidos e precisos. Ela divide o sistema em duas partes: uma para processar dados históricos e outra para dados em tempo real, que são depois combinados para fornecer informações finais.
Kappa
A arquitetura Kappa é uma simplificação da Lambda, focando apenas no processamento em tempo real. Ela não faz distinção entre dados históricos e novos, processando todos os dados como se fosse streaming. É ideal para casos onde o histórico não precisa de tratamento separado, simplificando a arquitetura.
O que elas têm em comum?
Essas arquiteturas têm em comum o objetivo de gerenciar, processar e analisar grandes volumes de dados para transformar informações brutas em insights valiosos. Todas elas lidam com o armazenamento e processamento de dados, embora de maneiras diferentes, para atender às necessidades específicas de análise e tomada de decisão.
Outro ponto comum é que elas precisam ser escaláveis, ou seja, capazes de crescer e lidar com volumes de dados cada vez maiores sem perder desempenho. Além disso, todas essas arquiteturas buscam garantir a eficiência no acesso e processamento dos dados, mesmo que os métodos e enfoques variem.
O que elas têm de diferente?
Essas diferenças se baseiam em suas abordagens para o armazenamento e processamento de dados, refletindo diferentes prioridades, como simplicidade versus flexibilidade ou precisão versus rapidez.
Lambda vs. Kappa
As arquiteturas Lambda e Kappa são frequentemente vistas como antagônicas devido à maneira como abordam o processamento de dados.
Como vimos no diagrama anterior, a Lambda usa duas camadas distintas para processar dados: uma para dados em lote (históricos) e outra para dados em tempo real. Essa dualidade permite combinar precisão (dados históricos) com rapidez (dados em tempo real), mas aumenta a complexidade, pois é necessário a junção de ambas em outra camada para se ter uma visão do todo.
Já a Kappa, por outro lado, simplifica o processo ao eliminar a camada de processamento em lote, tratando todos os dados como streaming (tempo real). Isso reduz a complexidade e é mais adequado para cenários onde o histórico e o tempo real não precisam ser tratados separadamente. Porém, traz outros desafios quanto a precisão dos dados, principalmente na compensação de transações ou integrações com sistemas que não possuem a capacidade de entregar os dados em tempo real.
Veja o post: O básico sobre engenharia de dados para entender como funciona a movimentação de dados na camada de lote e o post Streaming de dados pode ajudá-lo a entender um pouco mais sobre como funciona a movimentação de dados na camada de tempo real. Caso tenha interesse, o post DataOps, apresenta essa metodologia de forma mais detalhada.
Data Warehouse vs. Data Lake vs. Lakehouse
Como apresentado no diagrama, os Data warehouse, Data lake e Lakehouse também podem ser vistos como antagônicos em certos aspectos:
Data warehouse é altamente estruturado e otimizado para consultas rápidas e análises detalhadas, mas menos flexível e menos adequado para dados não estruturados.
Data lake é flexível e capaz de armazenar dados brutos de qualquer tipo, mas menos organizado e pode ser mais desafiador para consultas rápidas e precisas.
Lakehouse combina a flexibilidade do Data Lake com a estrutura do Data Warehouse, desafiando a separação clara entre as duas abordagens. Enquanto o Data Warehouse é altamente estruturado, o Lakehouse oferece uma solução híbrida, misturando características de ambos. O que traz os benefícios e desafios de ambos os cenários.
Elas podem ser usadas em conjunto?
Algumas dessas arquiteturas podem ser usadas em conjunto, dependendo das necessidades específicas do seu projeto. Aqui estão algumas combinações possíveis:
Lambda com outras arquiteturas
A arquitetura Lambda pode ser implementada sobre um Data lake ou Lakehouse. A camada de processamento em lote pode ler dados diretamente do Data lake ou Lakehouse, enquanto a camada de processamento em tempo real lida com dados que chegam continuamente, em geral, essa camada roda sobre um sistema de filas e tópicos como um Kafka, por exemplo.
Essa combinação permite flexibilidade no armazenamento de dados brutos e oferece processamento eficiente tanto para dados históricos quanto em tempo real.
Kappa com outras arquiteturas
A arquitetura Kappa pode usar um Data lake ou Lakehouse para armazenar dados brutos em tempo real, enquanto o processamento contínuo é realizado. Isso é útil em cenários onde todos os dados são tratados como streaming, mas ainda precisam ser armazenados em um formato bruto e acessível para futuras análises. É muito comum o uso de sistemas de filas e tópicos, assim como bancos de dados NoSQL.
Data warehouse e Data lake
Muitas organizações usam um Data lake para armazenar dados brutos e um Data Warehouse para armazenar dados estruturados e processados. O Data lake oferece flexibilidade e escalabilidade, enquanto o Data Warehouse facilita análises rápidas e estruturadas. Dados podem ser processados e refinados no Data lake antes de serem movidos para o Data Warehouse.
Lakehouse e Data warehouse
Embora o Lakehouse já combine características de Data Lake e Data Warehouse, ele pode ser usado junto com um Data Warehouse tradicional para suportar análises altamente estruturadas e exigentes, mantendo a flexibilidade para dados brutos e semi-estruturados. O Lakehouse serve como uma camada intermediária, integrando dados brutos e estruturados, enquanto o Data Warehouse fornece desempenho otimizado para consultas críticas.
Qual devo usar?
A escolha da arquitetura depende das necessidades específicas do seu projeto ou negócio. Mas de maneira geral há algumas diretivas que podemos seguir para nos orientarmos, vamos a algumas delas:
Tipos de dados
Estruturados vs. não estruturados: se você trabalha com muitos dados não estruturados (imagens, vídeos, logs, etc.), um Data Lake ou Lakehouse pode ser mais adequado. Para dados estruturados, como tabelas e relatórios, o Data Warehouse é uma boa escolha.
Velocidade de processamento
Tempo real vs. lote: se você precisa de análises e respostas em tempo real, considere a arquitetura Kappa ou Lambda. Para análises que podem ser feitas com mais calma e precisão, uma abordagem em lote, como Data Warehouse, pode ser suficiente.
Volume de dados
Escalabilidade: considere o volume atual de dados e o crescimento esperado. Arquiteturas como Data Lake e Lakehouse são projetadas para escalar com grandes volumes de dados, enquanto o Data Warehouse pode exigir mais recursos para escalar.
Complexidade de implementação
Facilidade de uso vs. flexibilidade: arquiteturas como Data warehouse são mais simples de implementar, mas podem ser menos flexíveis. Lambda e Lakehouse oferecem mais flexibilidade, mas podem ser mais complexas e caras de implementar.
Custo
Investimento inicial vs. custos operacionais: avalie o custo de implementação e operação. Arquiteturas como Lambda podem ter um custo operacional mais alto devido à sua complexidade, enquanto um Data lake pode ser mais barato para armazenar grandes volumes de dados, mas pode gerar custos adicionais para organização e manutenção.
Veja o post: Desmistificando a computação em nuvem para entender melhor a diferença entre investimento e custo operacional.
Governança e compliance
Segurança e gestão de dados: se a governança e a segurança dos dados são prioridades, um Data warehouse ou Lakehouse, com suas capacidades estruturadas e controles rígidos, podem ser mais adequados. Data lakes oferecem flexibilidade, mas podem ser mais desafiadores em termos de governança.
Veja o post: Além do gerenciamento: a estratégia essencial da governança de dados para entender um pouco mais sobre governança de dados.
Futuras necessidades de negócio
Flexibilidade para adaptação: considere a evolução do seu negócio e a necessidade de adaptar a arquitetura com o tempo. Se você prevê mudanças frequentes nos tipos de análise ou volumes de dados, uma arquitetura mais flexível, como Lakehouse, pode ser preferível.
Capacidade da Equipe
Habilidades técnicas disponíveis: avalie o nível de habilidade técnica da sua equipe. Arquiteturas mais complexas como Lambda ou Lakehouse exigem uma equipe mais experiente para implementação e manutenção, enquanto um Data Warehouse pode ser mais gerenciável por uma equipe menor.
Integração com sistemas existentes
Compatibilidade: verifique como a nova arquitetura se integrará com os sistemas e tecnologias existentes na sua organização. Algumas arquiteturas podem exigir mudanças significativas na infraestrutura atual.
Acredito que, considerando esses principais fatores, você poderá escolher a abordagem que melhor se alinha com as metas e os recursos da sua organização.
Conclusão
A gestão eficiente de grandes volumes de dados é um desafio que exige a escolha da arquitetura certa e um entendimento profundo das necessidades e objetivos do seu negócio. Como discutido, não existe uma solução única que atenda a todas as situações; a escolha da arquitetura ideal depende de múltiplos fatores, como tipo de dados, velocidade de processamento desejada, escalabilidade, e até mesmo a capacidade técnica da sua equipe.
Portanto, ao planejar a arquitetura dos sistemas de dados da sua organização, considere esses aspectos de forma cuidadosa e estratégica. Uma abordagem bem planejada facilitará a gestão de dados, e trará benefícios significativos para a tomada de decisões e para o crescimento sustentável do seu negócio.
Gostou do conteúdo e quer saber mais sobre como implementar a arquitetura ideal para sua organização? Inscreva-se na nossa newsletter e receba atualizações, dicas e conteúdos exclusivos diretamente no seu e-mail. Se precisar de consultoria personalizada, entre em contato!



